Содержание:
Что такое DOM и зачем он нужен?
В этой статье мы изучим: как создаётся веб-страница в браузере, что такое DOM и зачем он нужен, как строится DOM-дерево, а также какие бывают типы узлов и отношения между ними.
Как создаётся веб-страница?
Браузер, перед тем как показать вам запрашиваемую страницу, выполняет большое количество различных действий. Самое важное здесь понять, что браузер не работает с HTML-страницей напрямую как с текстом, а строит для этого DOM.
DOM – это объектная модель документа (Document Object Model). Представляет она собой древовидную структуру страницы, состоящую из узлов. Каждый узел в ней – это объект, который может иметь определённые свойства и методы. Иными словами, можно сказать, что DOM – это набор иерархически связанных между собой объектов.
Зачем браузер строит DOM? В основном это связано с тем, что прочитанный HTML-код ему нужно как-то представить в памяти и было решено, что оптимально это будет сделать в виде древовидной структуры. После того как браузер построил DOM, он его использует в дальнейших процессах, конечной целью которых является построения отображения этой страницы на экране.
Процесс перевода HTML-кода страницы в DOM выполняет парсер. При этом он это делает даже если HTML-код содержит ошибки, но так как он в данном случае это «понимает».
При этом DOM не является статической структурой. Её можно изменять с помощью JavaScript и тут же видеть эти изменения на экране. Для этого браузер нам предоставляет API. То есть благодаря DOM, мы можем с помощью JavaScript изменять содержимое страницы на лету. Таким образом, JavaScript – это ключевая технология для создания динамических веб-сайтов и веб-приложений. Без неё, каким-то других способом это сделать невозможно.
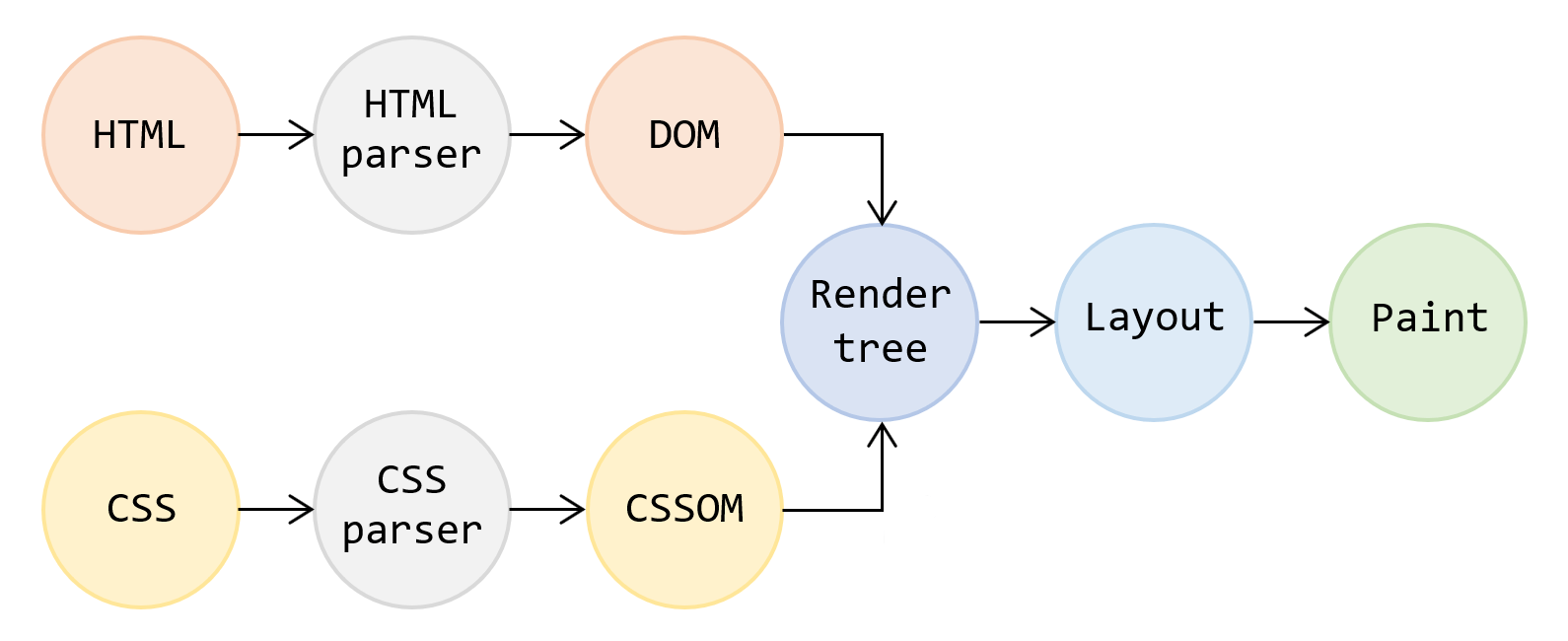
Перед тем как перейти к изучению DOM, рассмотрим сначала все основные этапы работ, которые браузер выполняет для преобразования исходного кода HTML-документа в отображение стилизованной и интерактивной картинки на экране. Кстати, этот процесс называется Critical Rendering Path (CRP).
Шаги CRP:
Хотя этот процесс состоит из большого количества шагов, их грубо можно представить в виде двух:
- Анализирует HTML-документ, чтобы определить то, что в конечном итоге нужно отобразить на странице;
- Выполняет отрисовку того что нужно отобразить.
Результатом первого этапа является формирование дерева рендеринга (render tree). Данное дерево содержит видимые элементы и текст, которые нужно отобразить на странице, и также связанные с ними стили. Это дерево дублирует структуру DOM, но включает как мы отметили выше только видимые элементы. В render tree каждый элемент содержит соответствующий ему объект DOM и рассчитанные для него стили. Таким образом, render tree описывает визуальное представление DOM.
Чтобы построить дерево рендеринга, браузеру нужны две вещи:
- DOM, который он формирует из полученного HTML-кода;
- CSSOM (CSS Object Model), который он строит из загруженных и распознанных стилей.
На втором этапе браузер выполняет отрисовку render tree. Для этого он:
- рассчитывает положение и размеры каждого элемента в render tree, этот шаг называется Layout;
- выполняет рисование, этот шаг называется Paint.
После Paint все нарисованные элементы находятся на одном слое. Для повышения производительности страницы браузер выполняет ещё один шаг, который называется Composite. В нем он группирует элементы по композиционным слоям. Именно благодаря этому этапу мы можем создать на странице плавную анимацию элементов при использовании таких свойств как transform, opacity. Так как изменение этих свойств вызовет только одну задачу Composite.
Для работы со слоями в Chrome есть отличный инструмент Layers.
Например, изменения свойства color вызовет сначала задачу Paint, а затем вероятнее всего последует Composite всех затронутых элементов.
Изменение width вызовет следующие задачи: Layout -> Paint -> Composite.
Layout и Paint – это ресурсоемкие процессы, поэтому для хорошей отзывчивости вашей страницы или веб-приложения, необходимо свести к минимуму операции которые их вызывают.
Список свойств, изменение которых вызывают Paint:
color;background;visibility;border-styleи другие.
Список свойств, изменение которых вызывает Layout:
widthиheight;paddingиmargin;display;border;top,left,rightиbottom;position;font-sizeи другие.
Кроме этого, Layout срабатывает не только при изменении CSS-свойств, но также, например когда мы хотим получить смещение элемента (el.offsetLeft, el.offsetTop и так далее) или его положение (el.clientLeft, el.clientTop и так далее), а также во многих других случаях. Более подробно ознакомиться с этими операциями можно здесь.
Чтобы понимать какую стоимость имеет то или иное свойство, можно установить расширение css-triggers для редактора кода VS Code:

Что же такое DOM?
DOM – это объектное представление исходного HTML-кода документа. Процесс формирования DOM происходит так: браузер получает HTML-код, парсит его и строит DOM.
Затем, как мы уже отмечали выше браузер использует DOM (а не исходный HTML) для строительства дерева рендеринга, потом выполняет layout и так далее.
Почему не использовать в этом случае просто HTML? Потому что HTML – это текст, и с ним невозможно работать так как есть. Для этого нужно его разобрать и создать на его основе объект, что и делает браузер. И этим объектом является DOM.
Итак, DOM – это объектная модель документа, которую браузер создаёт в памяти компьютера на основании HTML-кода.
По-простому, HTML-код – это текст страницы, а DOM – это объект, созданный браузером при парсинге этого текста.
Но, браузер использует DOM не только для выполнения процесса CRP, но также предоставляет нам программный доступ к нему. Следовательно, с помощью JavaScript мы можем изменять DOM.
DOM – это технология не только для браузеров и JavaScript. Существуют и другие инструменты, позволяющие работать с DOM. Например, работа с DOM может осуществляться серверными скриптами, после загрузки и парсинга ими HTML-страницы. Но это немного другая тема и мы не будем рассматривать её здесь.
Все объекты и методы, которые предоставляет браузер описаны в спецификации HTML DOM API, поддерживаемой W3C. С помощью них мы можем читать и изменять документ в памяти браузера.
Например, с помощью JavaScript мы можем:
- добавлять, изменять и удалять любые HTML-элементы на странице, в том числе их атрибуты и стили;
- получать доступ к данным формы и управлять ими;
- реагировать на все существующие HTML-события на странице и создавать новые;
- рисовать графику на HTML-элементе
<canvas>и многое другое.
При изменении DOM браузер проходит по шагам CRP и почти мгновенно обновляет изображение страницы. В результате у нас всегда отрисовка страницы соответствует DOM.
Благодаря тому, что JavaScript позволяет изменять DOM, мы можем создавать динамические и интерактивные веб-приложения и сайты. С помощью JavaScript мы можем менять всё что есть на странице. Сейчас в вебе практически нет сайтов, в которых не используется работа с DOM.
В браузере Chrome исходный HTML-код страницы, можно посмотреть во вкладке «Source» на панели «Инструменты веб-разработчика»:
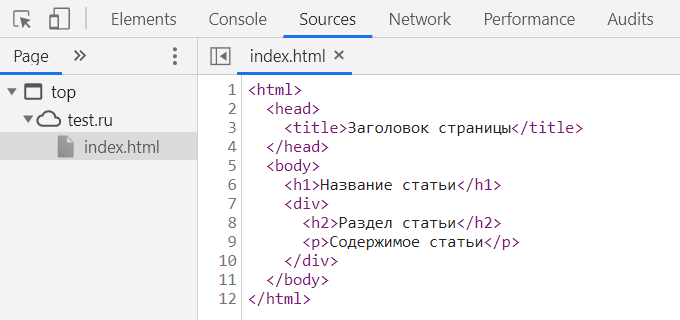
На вкладке Elements мы видим что-то очень похожее на DOM:
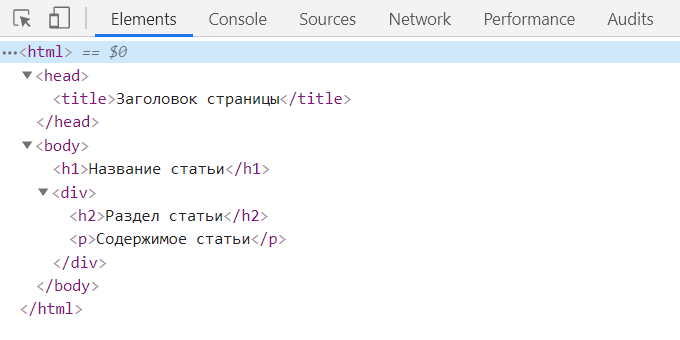
Однако DevTools включает сюда дополнительную информацию, которой нет в DOM. Отличным примером этого являются псевдоэлементы в CSS. Псевдоэлементы, созданные с помощью селекторов ::before и ::after, являются частью CSSOM и дерева рендеринга, и технически не являются частью DOM. Мы с ними не может взаимодействовать посредством JavaScript.
По факту DOM создается только из исходного HTML-документа и не включает псевдоэлементы. Но в инспекторе элементов DevTools они имеются.
Как строится DOM?
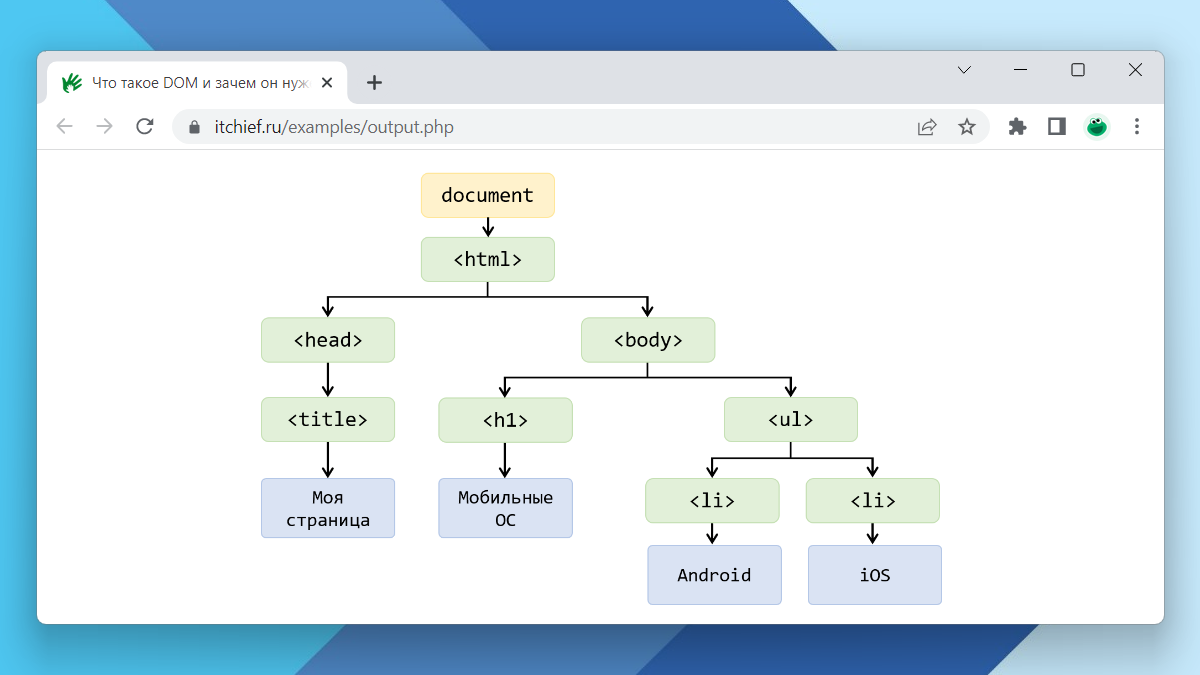
Перед тем, как перейти к DOM, сначала вспомним, что собой представляет исходный HTML-код документа. В качестве примера рассмотрим следующий:
HTML
<!doctype html>
<html lang="ru">
<head>
<title>Моя страница</title>
</head>
<body>
<h1>Мобильные ОС</h1>
<ul>
<li>Android</li>
<li>iOS</li>
</ul>
</body>
</html>Как вы уже знаете, HTML-документ – это обычный текстовый документ. Его код состоит из тегов, атрибутов, текста, комментариев и так далее. Очень важной сущностью в нём является HTML-элемент. На них всё строится. HTML-элемент в большинстве случаев состоит из открывающего и закрывающего тегов, между которыми располагается его содержимое. Например, HTML-элемент h1 имеет открывающий тег <h1>, закрывающий </h1> и содержимое «Моя страница». Кроме этого, тег может содержать дополнительную информацию посредством атрибутов. В этом коде атрибут имеется только у HTML-элемента <html>.
Также очень важно понимать, что в HTML-коде одни элементы вкладываются в другие. Например, <h1> вложен в <body>, а <body> в <html>. Это очень важная концепция, которая нам и позволяет нам создавать определённую разметку в HTML.
Теперь рассмотрим, как браузер на основании HTML-кода строит DOM. Объектная структура DOM представляет собой дерево узлов (узел на английском называется node). При этом DOM-узлы образуются из всего, что есть в HTML: тегов, текстового контента, комментариев и т.д.
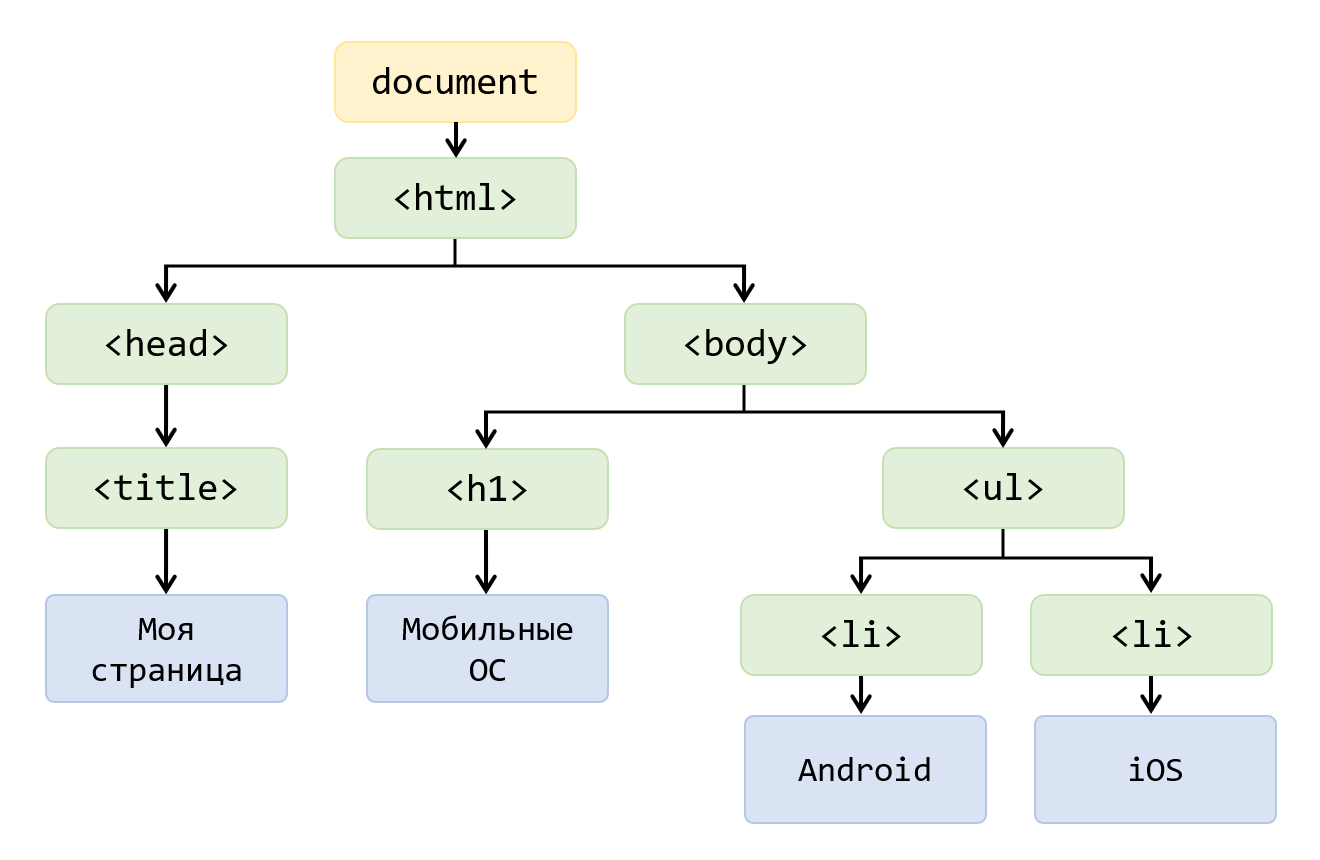
Корневым узлом DOM-дерева является объект document, он представляет сам этот документ. Далее в нём расположен узел <html>. Получить этот элемент в коде можно так:
JavaScript
const elHTML = document.documentElement;В <html> находятся 2 узла-элемента: <head> и <body>. Получить их в коде можно так:
JavaScript
const elHead = document.head;
const elBody = document.body;В <head> находится DOM-узел <title>:
JavaScript
// получим <title> и присвоим его переменной elTitle
const elTitle = document.title;В <title> находится текстовый узел. Теперь перейдём к <body>. В нём находятся 2 элемента <h1> и <ul>, и так далее.
При этом, как вы уже поняли, узлы в зависимости от того, чем они образованы делятся на разные типы. В DOM выделяют:
- узел, представляющий собой весь документ; этим узлом является объект
document; он выступает входной точкой в DOM; - узлы, образованные тегами, их называют узлами-элементами или просто элементами;
- текстовые узлы, они образуются текстом внутри элементов;
- узлы-комментарии и так далее.
Имеются и другие типы узлов, но на практике в основном используются только перечисленные выше.
Каждый узел в дереве DOM является объектом. Но при этом формируют структуру DOM только узлы-элементы. Текстовые узлы, например, содержат в себе только текст. Они не могут содержать внутри себя другие узлы. Поэтому вся работа с DOM в основном связана с узлами-элементами.
Кстати, директива <!doctype html> тоже является DOM-узлом. Но она нам не интересна, поэтому на схеме мы её опустили.
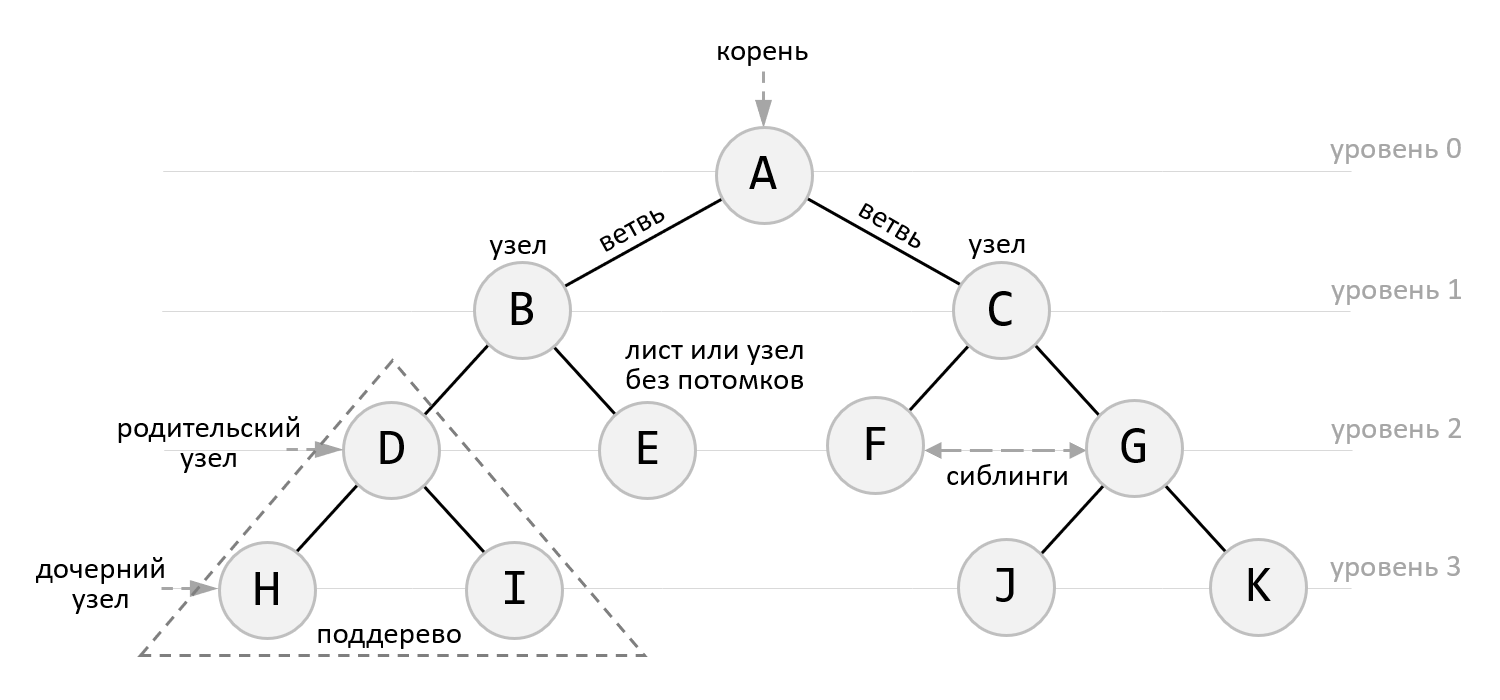
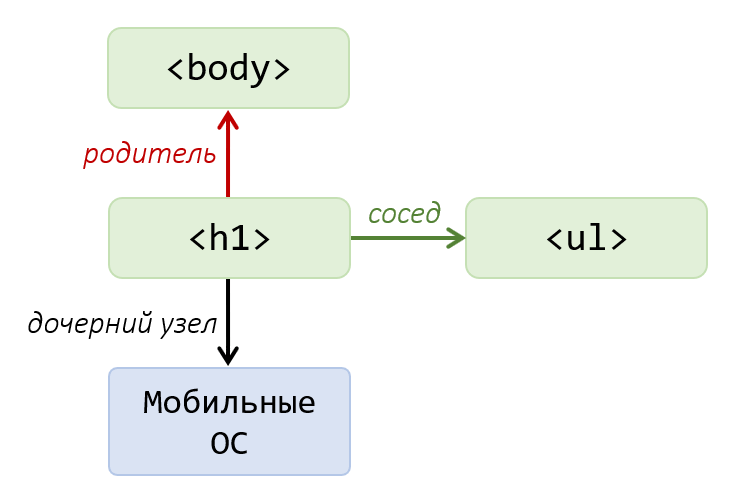
Чтобы перемещаться по узлам DOM-дерева нужно знать какие они имеют отношения. Зная их можно будет выбирать правильные свойства и методы. Связи между узлами, определяются их вложенностью. Каждый узел в DOM может иметь следующие виды отношений:
- родитель – это узел, в котором он непосредственно расположен; при этом родитель у узла может быть только один; также узел может не иметь родителя, в данном примере им является
document; - дети или дочерние узлы – это все узлы, которые расположены непосредственно в нём; например, узел
<ul>имеет 2 детей; - соседи или сиблинги – это узлы, которые имеют такого же родителя что и этот узел;
- предки – это его родитель, родитель его родителя и так далее;
- потомки – это все узлы, которые расположены в нем, то есть это его дети, а также дети его детей и так далее.
Например, узел-элемент <h1> имеет в качестве родителя <body>. Ребенок у него один – это текстовый узел «Мобильные ОС». Сосед у него тоже только один – это <ul>.
Теперь рассмотрим, каких предков имеет текстовый узел «iOS». У него они следующие: <li>, <ul>, <body> и <html>.
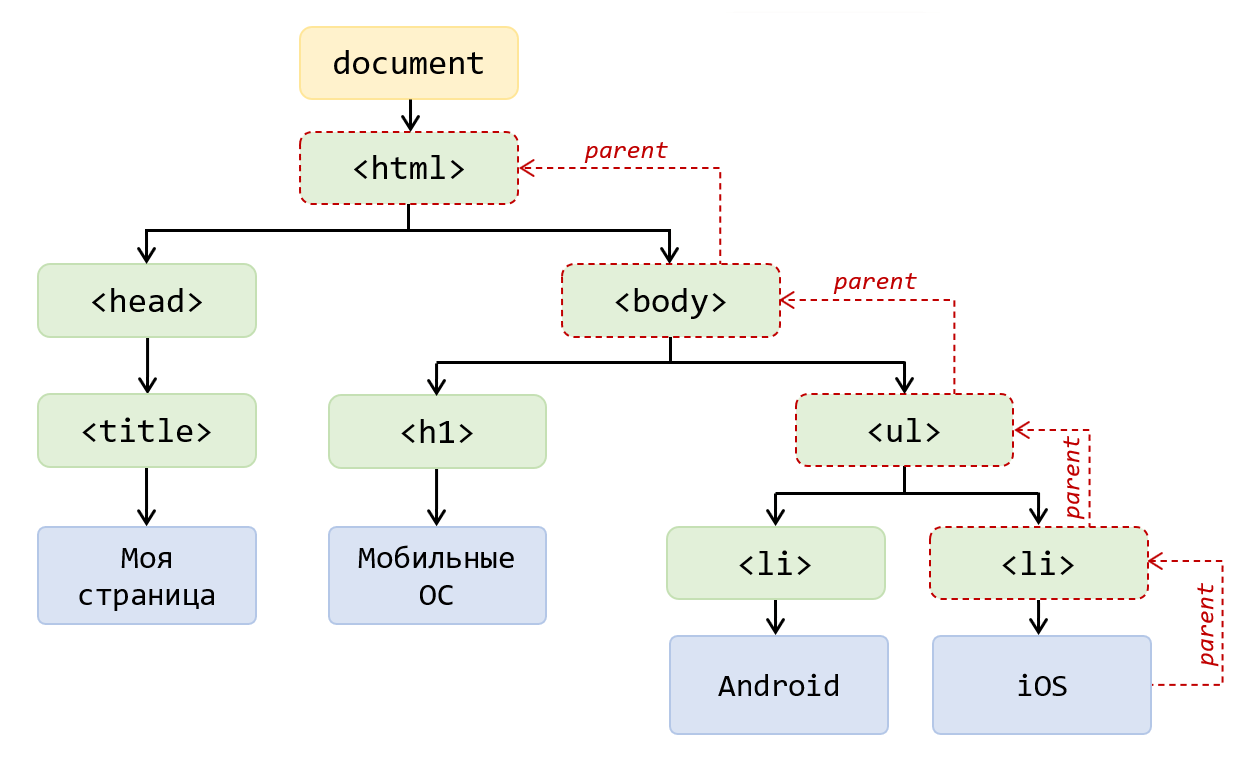
У элемента <head> 2 потомка: <title> и текстовый узел «Моя страница».
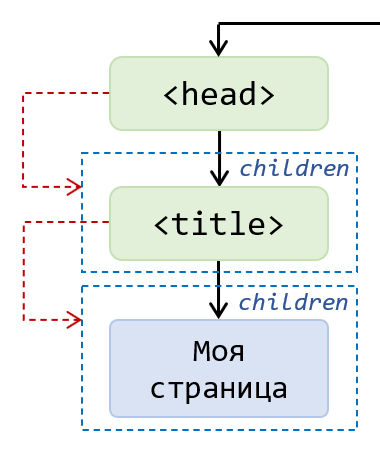
Зачем нужно знать, как строится DOM-дерево? Во-первых, это понимание той среды, в которой вы хотите что-то изменять. Во-вторых, большинство действий при работе с DOM сводится к поиску нужных элементов. Но не зная как устроено DOM-дерево и отношения между узлами, найти что-то в нём будет достаточно затруднительно.
Задания
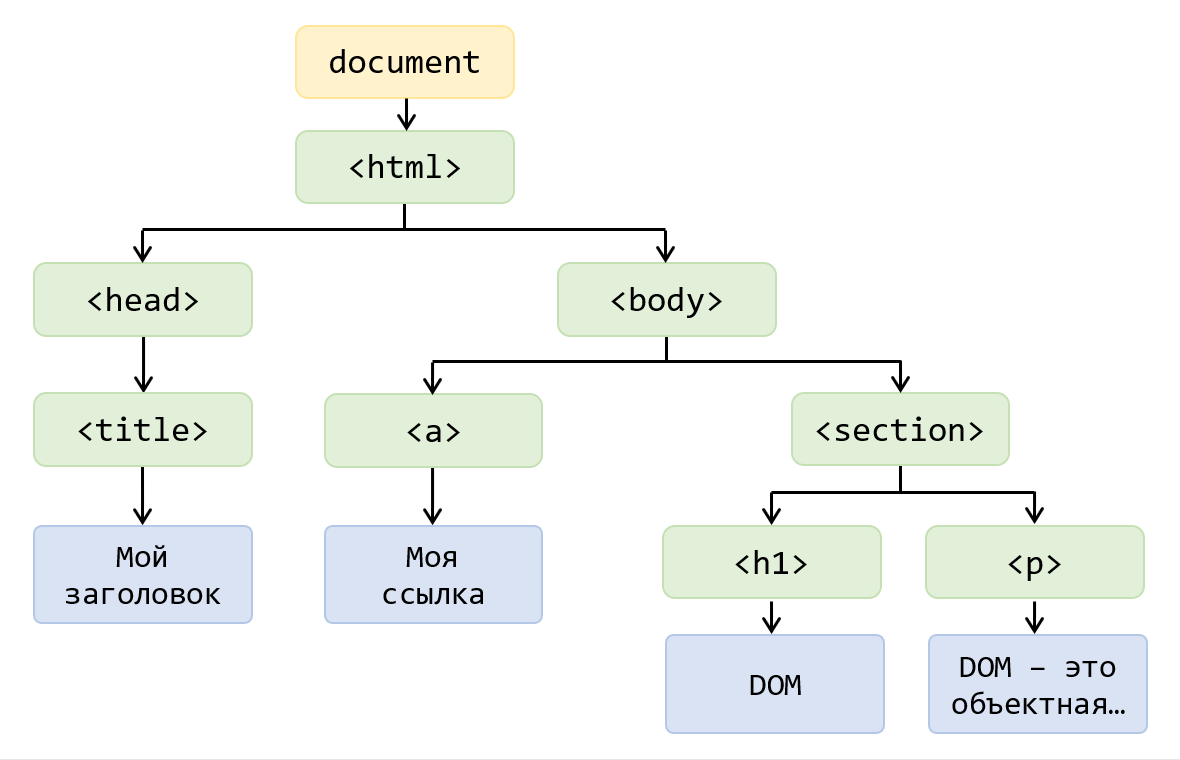
1. Представленное DOM-дерево преобразуйте обратно в HTML-код:
Следующая тема: Узлы DOM-дерева.
Комментарии: 8
Обработку строк, если вы работаете на VBA, можно выполнить используя соответствующие методы этого языка.
Заранее спасибо.
Вам нужно в VBA получить HTML-документ. А далее с помощью методов получить этот текстовый узел.